Tam is likely the unsung hero of this paper and all of Cole’s successes. I have no citations for that fact, but look at that sweet kitty face.
Lets just take a second to dote on them and highlight the reasons (something I’m sure is making them cringe as they read this): (1) they have A-FREAKING-TON of publications as a grad student, (2) people see them as independent and their research thinking is 1000% on point for a starting faculty (even though they are a few years away), and (3) they….. WON THE 2023 MARY S. CERNEY STUDENT PAPER AWARD FROM THE SOCIETY OF PERSONALITY ASSESSMENT.
Yup, thats right. Cole’s working conducted using three conditions of simulated respondents on MMPI-3 over-reporting scales (mTBI, PTSD, co-morbid) was recognized as making an impact on the field. I’ve always been a huge fan of that paper (click me to read it), but clearly everyone else is as well. Great work Cole.
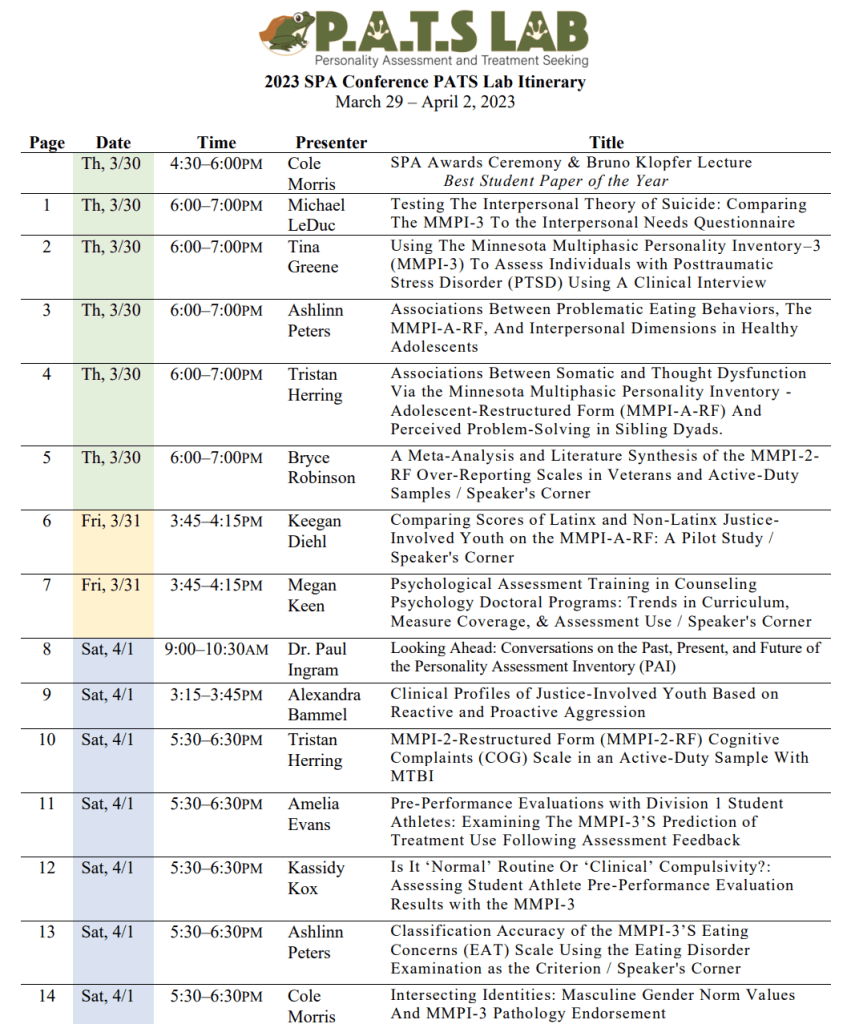
Well, March is going to be exciting! PATS is headed to SPA again and the amazing Tina Greene put together an awesome program guide to help those who are at SPA who want to see what our lab is doing – and for the PATS lab to keep track of all 14(!!) different presentations/awards. Click here to download the PDF guide to the program. Below is a one page summary of the research title/date-time/and lead author.
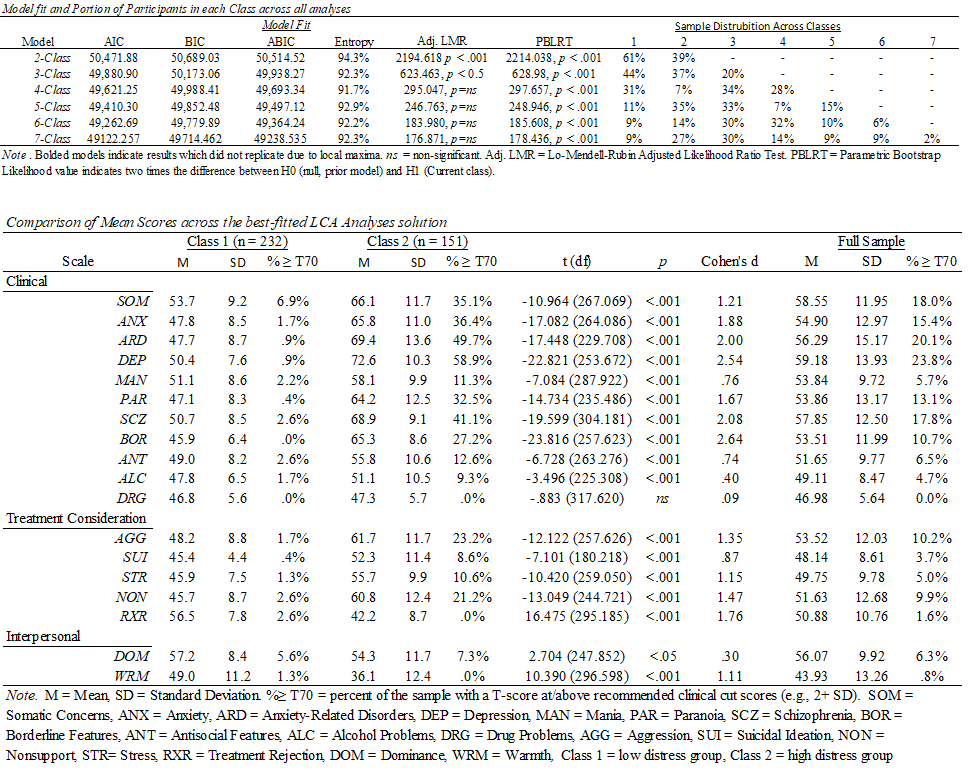
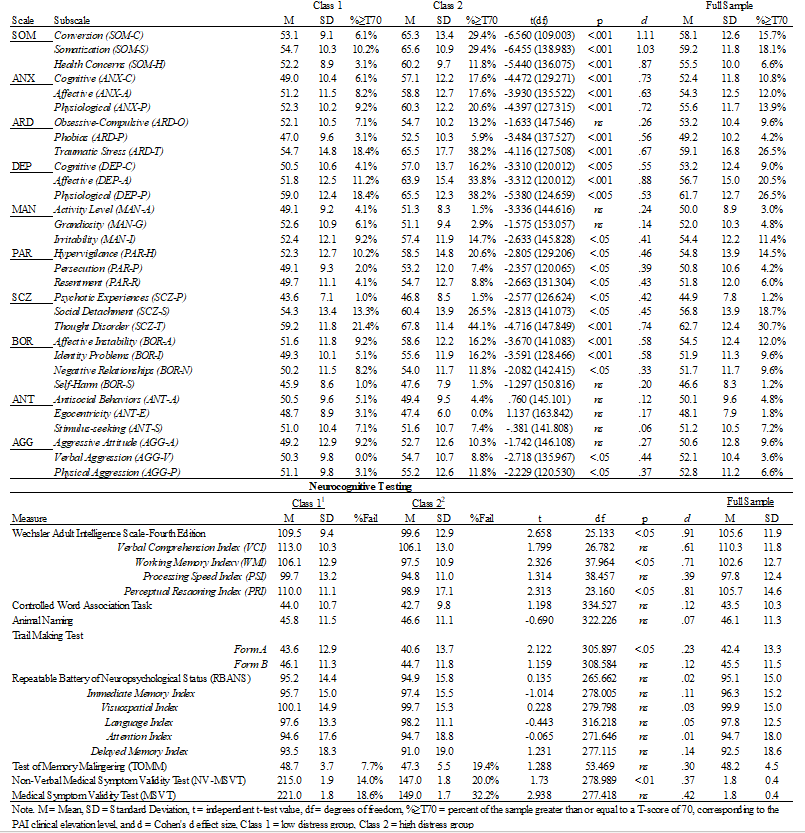
Previous work has examined PAI response patterns on those with mild traumatic brain injury (mTBI), but these research efforts have faced a number of notable challenges. Accordingly, findings between studies have often contradicted. There are a variety of reasons for these contradictions including, but not limited to, that prior research has: (1) not excluded individuals from analysis with failed validity testing, meaning that data analyzed is likely not fully valid/reliable, (2) the inappropriate use of item-level grouping analyses (factor analysis) to identify groups of participants, which is better suited to cluster/profile analysis, (3) insufficient sample sizes to conduct any of the analyses undertaken (i.e., far fewer participants per observed variable analyzed than required; see Brown, 2015), (4) interpretation of scale means that are entirely normative (i.e., T-score mean of 50, corresponding to the normative sample’s mean) as indicating a clinical pattern, and (5) use of analyses without fit statistics, making comparison between identified cluster solutions tentative at best. We aimed to address these limitations through our study, now in press at Archives in Clinical Neuropsychology.CLICK ME TO DOWNLOAD A PREPRINT.
Taking these challenges into account, as well as the unique need to focus on military populations who face higher head injury rates than others, our recent paper used latent profile analysis (LPA) to explore potential groups of mTBI diagnosed respondents on the Personality Assessment Inventory (PAI). Although prior and related mTBI work (see above) had identified a variety of cluster solutions (2-4 classes), we hypothesized that we would not find meaningful classes. Rather, class extraction would represent a continuous underlying pattern of symptom severity – not functionally distinct groups. We grounded this finding in some prior work we conducted on PTSD groups in the PAI (see Ingram et al., 2022; Click for PDF) as well as the first- factor problem of the PAI.
I pulled a few sentences that I think sum up everything particularly well from the discussion below to summarize these results.
The findings here have a few distinct implications: (1) prior group identification efforts are not replicated in AD personnel and may, instead, represent broader issues with analysis discussed above rather than meaningful findings, (2) the first factor problem (general elevation of substantive clinical scales due to distress, not specific pathology) may also play a role in the observed patterns and should be addressed to aid in the future of the PAI (see Morey, 1996 for discussion of the first factor problem).
As an aside, Tristan (post-bac RA) was the second author on this paper and absolutely killed it with his work on the paper. Not only did he handle about half of the analyses (everything not doing latent clustering), he also learned about how these cluster method work so that he could write some of the discussion and handled 95% of all edits needed for the revise and resubmit. Really awesome work and hats off to him!
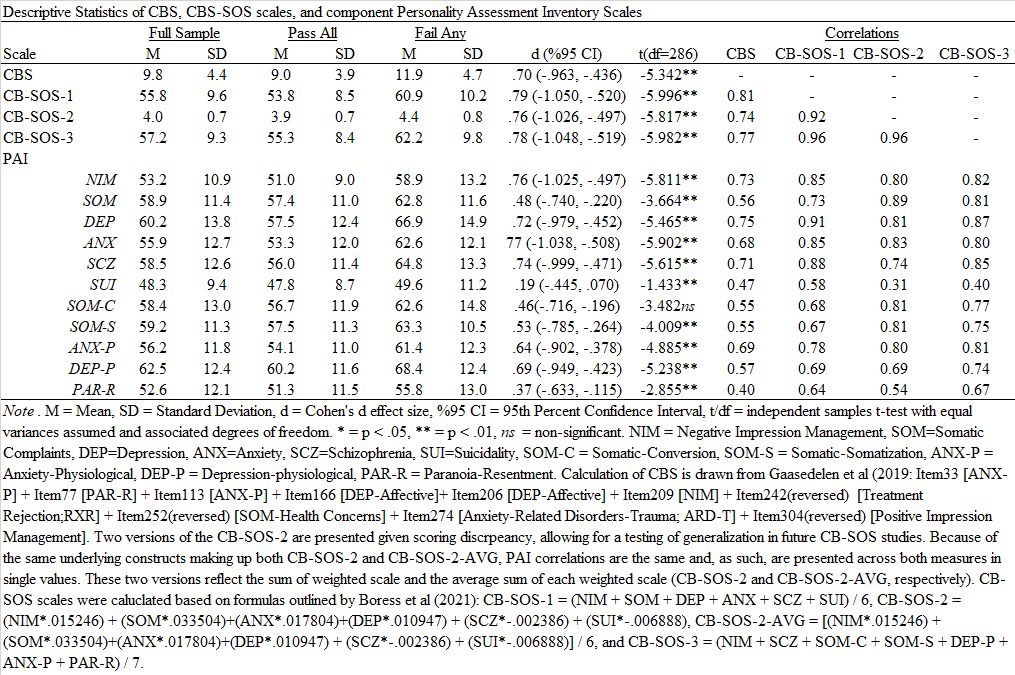
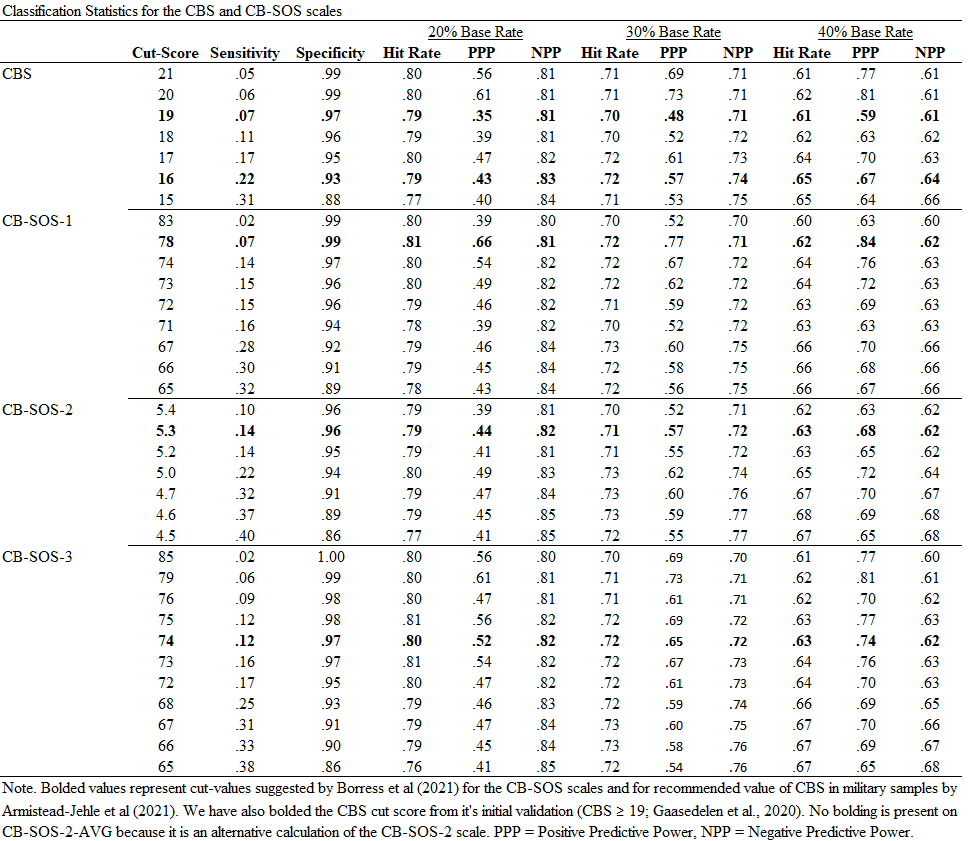
We had another paper published recently looking at the detection of cognitive over-reporting on the PAI, examining the CBS again (see also Armistead-Jehle et al., 2021) along with the new CB-SOS scales. The SOS scales offer a scale level approach to incorporating a cognitive-specific over-reporting scale, rather than needing items like CBS. This paper is in press in the The Journal of Military Psychology with Tristan Herring (lab post-bac), Cole Morris (advanced doctoral student), and the amazing Dr. Pat Armistead-Jehle.
Medium effects were observed between those passing and failing PVTs across all scales. The CB-SOS scales have high specificity (≥.90) but low sensitivity across suggested cut scores. While all CB-SOS were able to achieve .90, lower scores were typically needed. CBS demonstrated incremental validity beyond CB-SOS-1 and CB-SOS-3; only CB-SOS-2 was incremental beyond CBS. In a military sample, the CB-SOS scales have more limited sensitivity than in its original validation, indicating an area of limited utility despite easier calculation. The CBS performs comparably, if not better, than CB-SOS scales. CB-SOS-2’s differences in performance in this study and its initial validation suggest that its psychometric properties may be sample dependent. Given their ease of calculation and relatively high specificity, our study supports the interpretation of elevated CB-SOS scores indicate those who are likely to fail concurrent PVTs. Specific results are provided below.
These findings are commensurate with the initial CB-SOS validation study (Boress et al., 2021) and to the recent study on CB-SOS with Veterans (Shura et al., in press). However, results are also distinct as they highlight the need for different cut scores to meet the comparable classification rates. Within active-duty personnel, CB-SOS and CBS perform in a largely similar manner (e.g., comparable sensitivity, specificity, positive and negative predictive power); however, CBS has a small amount of incremental, predictive utility suggesting that it may be the front-line scale. However, calculation of the CBS requires access to PAI item responses and is somewhat more cumbersome to acquire. When those are not available, the CB-SOS scales seem to represent good alternatives to assess cognitive symptom over-reporting.
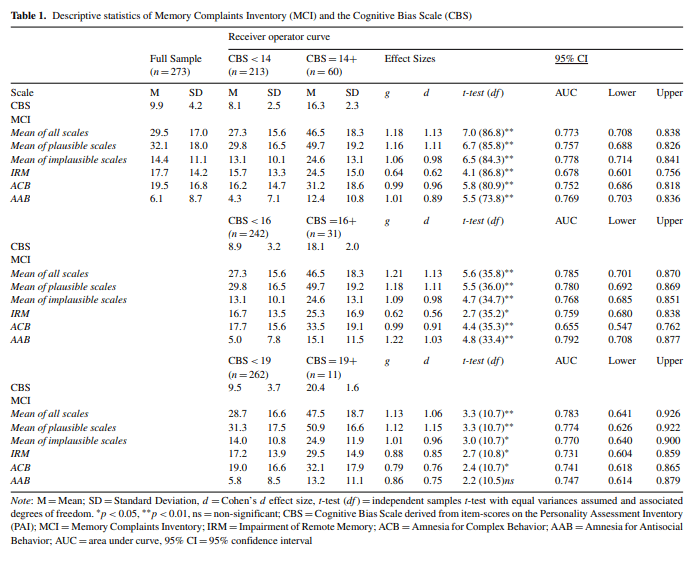
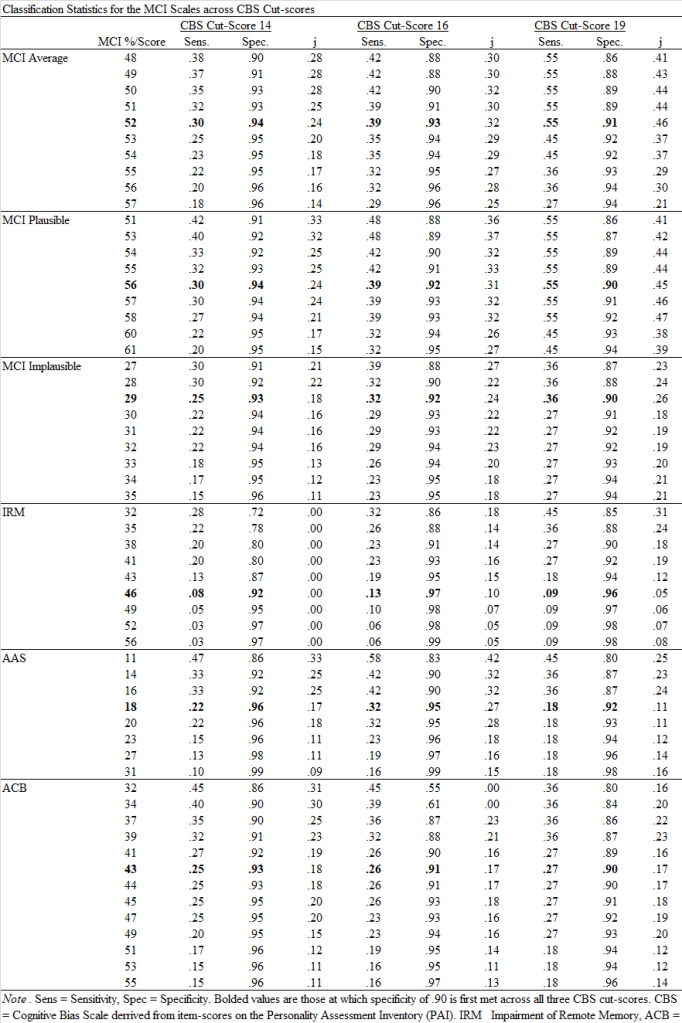
This was another awesome project to do with the fantastic Dr. Pat Armistead-Jehle. One of the major shortcomings of the Green’s MCI is its lack of of work with other SVTs, despite the limited work to date cross validating the MCI with those measures (Armistead-Jehle & Shura, 2022). This study was intended to expanded that limited research, using the recently validated CBS scale from the PAI as the criterion (related, to see Shura et al, 2022 which I recently helped published). You can download a pdf copy of the article HERE.
Short version of findings from this new work is that the MCI has good evidence of classification accuracy using recommended cut-scores. We only used one SVT criterion and similar measures on other broadband measures (e.g., MMPI-3’s RBS scale) are needed to further this line of work. Below are the classification and effect metrics across each of the MCI scales.
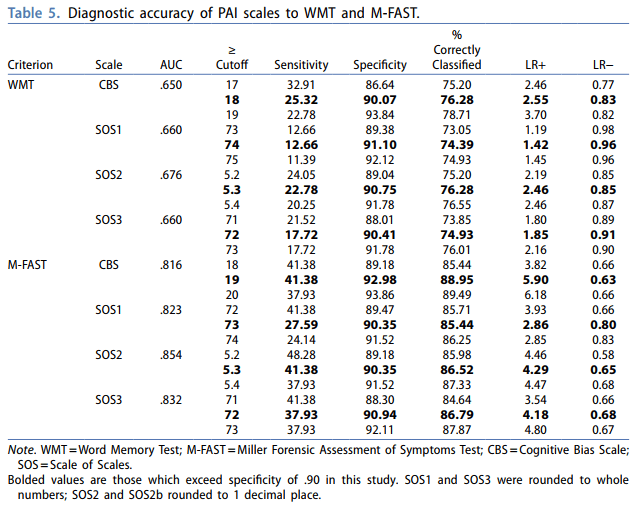
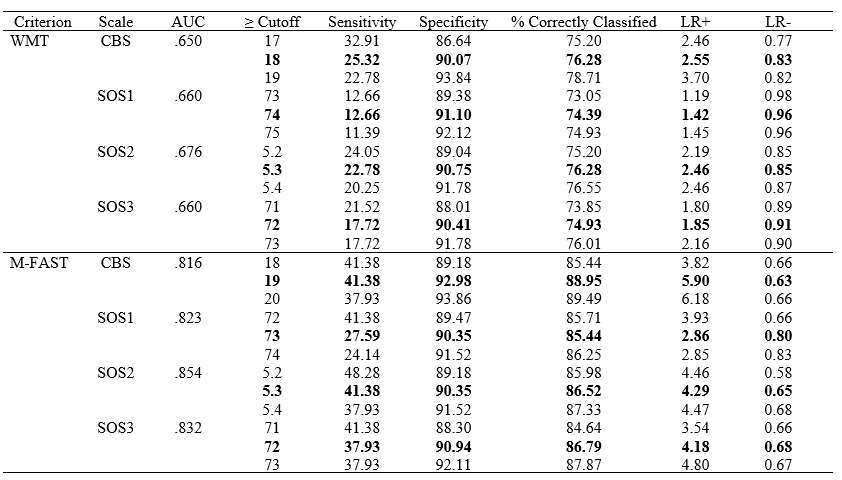
Recently, a collaboration with the wonderful folks at the Salisbury Veteran Affairs MIRECC was published in The Clinical Neuropsychologist. In this article we examined the CBS and CB-SOS scales for the PAI to determine their detection of over-reported cognitive symptoms (Word Memory Test Criterion) and general psychopathology over-reporting (M-Fast Criterion) in a sample of post-deployment Veterans. This is an exciting article that continues to grow validity detection effectiveness and options on the PAI and the article also highlights some very important considerations for traditional conceptualizations of distinct over-reporting strategies (e.g., cognitive, somatic, and psychological distress patterns; Sweet et al., 2021).
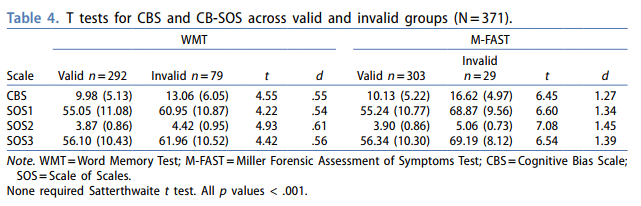
Specifically, results highlight that scales designed to assess cognitive domains may not be distinct from other domains, in part because of the non-distinct item content used to generate the scales, even when using “boot strapped floor effect” approaches to scale generation (see Burchett & Bagby, click me). Such findings are supported by the overall classification rates contrasted between M-fast and WMT when contrasting 90% specificity value points (Table 5), as well as higher sensitivity. While it is possible that this pattern is sample dependent, this pattern is also evident on other instruments/cognitive over-reporting scales (e.g., Butcher et al., 2008). Thus, these findings highlight a specific instrument development need and have direct implications moving forward for how instrument embedded validity scales should be conceptualized.
From the discussion in this recently published Shura et al (2022) paper, “Revisions to testing measures that aim to expand cognitive overreporting assessment, and to focus on this domain of symptom response (Sherman et al., 2020), may benefit from increased emphasis on the development of cognitively focused items based on a priori, empirically based content. Explicit use of validity detection patterns (Rogers & Shuman, 2005) at early developmental phases (e.g. creating specific items that highlight symptom incongruence or symptom rarity; Rogers & Bender, 2018), rather than post-hoc identification of items that may not measure those constructs explicitly is warranted. Well-specified item-pool revision efforts specific to validity testing needs and standards (Sherman et al., 2020; Martin et al., 2015) may not only improve general and longstanding classification difficulties (i.e. low sensitivity), but the distinctiveness of symptom clusters. Even if the overlapping PVT/SVT performance does not resolve entirely as a function of shifted developmental priorities, placing an increased emphasis on validity content development at the test revision stage remains necessary. Broadband measures are widely and historically preferred because of their SVTs (Ben-Porath & Waller, 1992; Russo, 2018), as well as the broader growth in focus on SVT-related research (Sweet et al., 2021). Research on validity scales tends to use either PVT or SVT criterion as an outcome, but rarely within the same study. Given the potential for effective performance on the related (but not overlapping) constructs of PVTs and SVTs, the inclusion of distinct criterion measures that assess divergent over-reporting symptom sets (somatic, cognitive, or psychological; Sweet et al., 2021) is also merited.”
The lab is working extensively to expand the research on over-reporting detection on the PAI for Cognitive symptoms. The most recent paper is part of a new collaboration with the staff at the Hefner VA MIREC in Salisbury, North Carolina, including the fantastic Dr. Robert Shura (as well as other training staff there). It is the latest in the continued collaboration with Dr. Pat Armistead-Jehle. We used a sample of Veterans to explore how well the CBS and CB-SOS scales worked in detecting invalid responding, based on performance on a PVT (Word Memory Test) and a SVT (M-FAST). This paper is in press at The Clinical Neuropsychologist using the following citation:
Shura, R., Ingram, P.B., Miskey, H.M., Martindale, S.L., Rowland, J.A., & Armistead-Jehle, P. (In Press). Validation of the Personality Assessment Inventory (PAI) Cognitive Bias (CBS) and Cognitive Bias Scale of Scales (CB-SOS) in a Post-Deployment Veteran Sample. The Clinical Neuropsychologist
Following exclusions for non-content responding, we used 371 Veterans assessed in a neuropsychology clinic, pass and fail group differences were significant with moderate effect sizes for all cognitive bias scales between the WMT-classified groups (d = .52 – .55), and large effect sizes between the M-FAST-classified groups (d = 1.27 – 1.45). AUC effect sizes were moderate across the WMT-classified groups (.650 – .676) and large across M-FAST-classified groups (.816 – .854). When specificity was set to .90, sensitivity was higher for M-FAST and the CBS performed the best (sensitivity = .42). Thus, the CBS and CB-SOS scales seem to better detect symptom invalidity than performance invalidity in Veterans using cutoff scores similar to those found in prior studies with non-Veterans.
I’m thrilled to have another paper out with the fantastic Dr. Pat Armistead-Jehle which focuses on validity assessment and scale effectiveness. It is still in press so no formal PDFS yet, but it will appear in Archives of Clinical Neuropsychology. As the first step to interpretation of substantive scale use, validation of validity efforts remains a critical step to effective clinical assessment. There remains a paucity of work on memory complaint SVTs relative to other domains of over-reporting (e.g., psychopathology; see Sweet et al., 2021), and the Memory Complaints Inventory (MCI) by Paul Green is the leading measure which does so independent of broadband personality assessment. However, no work had related performance on this instrument to the PAI, despite their frequent concurrent use in neuropsychological evaluations. I provide cut score effectiveness on the MCI using the CBS scale (the PAI’s cognitive SVT) below.
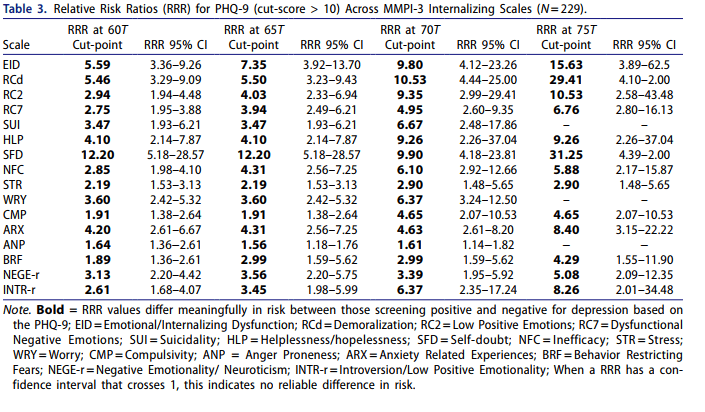
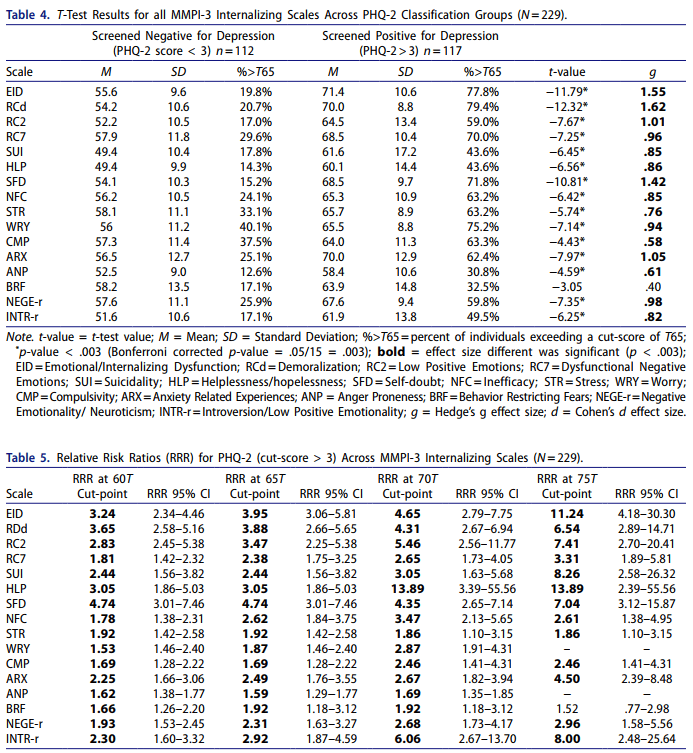
Cole recently published yet another amazing paper, expanding the ability to use contemporary personality assessment measures and link their use with other clinical practices. In this case, they examined how common depression screens (i.e., PHQ-2/9) used in medical settings relate to the more comprehensive MMPI-3. So useful, building directly on an article by David McCord on the MMPI-2-RF. Linked below are the tables which are directly related to screening effectiveness. Psychologists, as well as other health/mental health professionals, should see elevated scores on the PHQ (i.e., those exceeding clinical cut score recommendations; PHQ-9 of 9, PHQ-2 of 3) as being most associated with general internalizing pathology, and feelings of self-doubt, helplessness, and demoralization. Likewise, risk of suicidality is also significantly elevated at these cut scores and should be evaluated.
More excellent work from TTU Clinical Psych student Becca Bergquist was just accepted to the Journal of Clinical Psychology! Long story short, we were curious if our national sample of clinical/counseling students could give us a better sense of the factors influencing if they plan to incorporate assessment into their careers (as a major component of psychologist professional identity).
Developing long-term professional practice goals is a critical step not only for trainees, but also for designing effective educational approaches to guide competent psychological assessment practice. Thus, understanding factors that shape decisions to engage in this domain of competence are needed, and must include evaluations of self-reported and actual competency as distinct constructs.
Survey invitations were sent to training director(s) (TD) at APA-accredited HSP programs that include substantive training in Clinical or Counseling psychology (including those listed as having combined-type programs). Programs were considered for inclusion if they were located within the United States and listed as accredited on the APA website in January of 2019 (APA, 2018). Our final sample (n = 414; see Table 1) of trainee respondents (PhD = 64%; PsyD = 35.3%) were on average of 27.8 years old (SD = 3.5) and identified as female (79.5%) and white (82.4%). Most trainees were enrolled in a Clinical training program (77.8%) rather than Counseling (17.6%) or a combined type (4.6%) program. This recruitment means that we are talking about PRE-COVID understandings of assessment, with no tele-assessment emphasis.
The findings from this study have four distinct and important themes which warrant additional consideration: (a) students’ intention to utilize assessments in their future careers is incrementally predicted by self-reported competence beyond program characteristics, respondent demographics, and career setting aspirations, (b) self-reported competency plays a larger role than performance-based competency when assessing trainees’ career intentions to involve assessment, (c) graduate training and practice experiences in assessment were insignificant predictors of trainees’ intentions after accounting for the other predictors within the model and, (d) self-reported and performance-based competence influences trainees’ perception of and engagement in training experiences.
Findings suggest that a focus on self-awareness and self-knowledge in competency development (Kaslow et al., 2018) would benefit from ensuring trainee perceptions of their competency align with benchmarked progression. Trainees with high assessment competence (both self-reported and performance-based) reported significantly more hands-on instrument use than their peers with lower assessment competencies. This pattern of findings suggests that efforts to foster assessment competence may be shaped by coursework and practicum training. Thus, efforts to increase exposure and training with assessments may result in greater competence and career engagement. While the aforementioned training components seem to be promising targets for increasing trainee assessment capability, implementing and evaluating these efforts cannot be done without modifying existing training frameworks. Indeed, research generally suggests that traditionally-defined assessment competence, which stems from knowledge and skills obtained during graduate coursework and clinical practicum, does not contribute meaningfully to perceptions of professional competence in practicing psychologists (Neimeyer et al., 2012b).