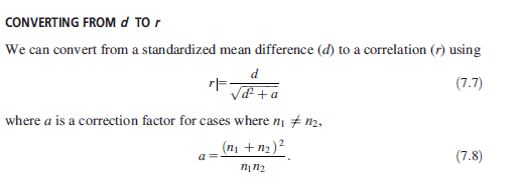I like to reflect on all the old classic “summary of science” books written by the various titans of our field. Revisiting some of these earlier discourses has given some interesting insight into often overlooked, but widely known and acknowledged, facts about the field. I didn’t really edit this, and its more of a late night “All the Things Graduate School Taught Me” ramble than anything else.
Psychological Facts
Fact #1. Nothing I’m going to say will shock you, much less outrage you, even though it should.
Despite people screaming from the top of their lungs about the following facts, we continue to mosey along as if none of these things are going on around us, almost in a dissociative fugue. The names of the folks who have been screaming these facts are synonymous with graduate education (e.g., Meehl, Kuhn, etc.), and psychology even more explicitly (Lillienfield, Meehl, Lykken, and others etc.- linked a few good reads). So yeh, you’re not going to be surprised, or shocked, or even upset most likely. It’s just going to be like “Yeh, I know.”
Fact #2. Almost nothing that you think you know about psychology is true.
Simply put, we continue to repeat the same old myths and legends about psychology that are not based in factual history (except the cocaine and Freud thing, that’s true). These factually inaccurate histories are embedded in how we teach “fundamental historical studies” (e.g., studies which are hailed as classics but are, in fact, complete fraud – such as the Standford Prison study) and how we talk about major theorists. Paul Meehl, an ardent proponent of Popper’s falsifiability approach to clinical science, was a Freudian despite a lack of evidence, and he found no issue in this, seeming at first glance, incongruence. He explained it noting that a lack of evidence does not indicate our inability in the future to find evidence, as told by Grant Dahlstrom with whom he was a close personal friend (Dahlstrom, 1991). Frued, as another instance, wasn’t cold or stand offish the way analytic methods are described, rather he invited clients on extended family vacations. There was no real data supporting most of the social psychology theories (e.g., Milgram, Zimbardo, etc.). Repeating again and again across topic, anything which is not based on biological processes (don’t get excited, see below) that you learned in undergraduate is about 50% false. This isn’t even the first time you’ve heard that, and I’m not the only one who’s said something like that to you.
Fact #3. Even biological processes are not understood, and we are still discovering organs.
The recent serotonin crisis in which major studies began to reveal that the leading treatment for depression doesn’t relate to depression at all. Research Domain Criteria (RDoC), the leading paradigm for linking behavior to biology via billions of dollars in federal funding, failed to produce meaning evidence of anything. We don’t know why we have some basic organs and have recently found new organs even (you can debate if the recent addition qualifies as an organ or not, but fact remains it is by technicality). We understand some things and can account for its prediction in a clear and precise pattern, akin to the logarithmic unit associated with “decibans” of a Turing Scale (e.g., smallest dose-response ratio needed to produce a given change in weight of evidence against an outcome). The “Turing Test” used as an analogous test of AI achievement (when is a computer sentient), requires the same conceptual approach. Rather than this empirical approach, we use associative conclusions which preclude causal implications (i.e., this is why we didn’t know serotonin has nothing to do with depression despite the money, lives, time, and resources spent studying it until now).
Treatment Science
Fact #1. We know basically one thing that underlies our entire theory of susceptibility: we regress under stress.
“It can be assumed that each personality type has idiosyncratic susceptibilities to particular stressors and when the dynamic system of such a type is under stress, it will manifest features of psychopathology characteristic of that type.” – Grant Dahlstrom
Thus, all theories related to first factor problems in assessment, stress response, etc. stem from the basic principle that “Under stress, we regress based on our identity. A central first problem must be understanding (1) prediction of who regresses the most (i.e., sees the largest stress response), a question of latent class probability, and (2) the specific factors which are likely to occur in tandem with such regressions (e.g., pre, peri and post risk and resiliency factors). These factors are likely numerous in name but limited in conceptualization.
Fact #2. There is zero evidence of a single causal factor of psychotherapy change.
“I spent 13 years at NIMH really pushing on the neuroscience and genetics of mental disorders, and when I look back on that I realize that while I think I succeeded at getting lots of really cool papers published by cool scientists at fairly large costs—I think $20 billion—I don’t think we moved the needle in reducing suicide, reducing hospitalizations, improving recovery for the tens of millions of people who have mental illness.”
– Tom Insel, Director of the National Institute of Health from 2002 until 2015.
Across all psychotherapy research, we have failed to produce novel changes in effectiveness despite decades of research and billions of dollars. Most of the studies will be efficacy stuffies, using some form of a wait list control (or active control) to contrast a treatment outcome. Effectiveness studies are less common, whereas studies of fidelity remain high. There will be no differences between most treatment component studies (e.g., dismantling studies of specific components, interventions for the same disorder across different methods). The effect sizes, regardless of metric, will measure approximately .70 to 1.25 at the conclusion of treatment. In follow-ups on the same evaluation metrics (e.g., self-report or other) will produce a smaller effect size, typically .5 to .75. Our current approach to studying change has yet to produce any evidence that we can explain any part of it. To make things even worse, we don’t even know how to describe the same phenomenon to each other effectively. As an analogy, we spend more time fighting over what story to tell the baby at bedtime (e.g., treatment myth, as per Frank and Frank’s contextual model of psychotherapy would term it) than discussing how to get the baby to sleep (e.g., better treatment outcome which is the purpose of the actual ritual of a bed time story). Likewise, psychotherapy interventions, even when conducted under 100% fidelity to the ideal treatment study for a given psychotherapy treatment in a highly specific sample (e.g., CBT for Depression in Veterans with a history of traumatic brain injury), can be explained fully by any other theory without exception. I should note that most therapist identify with distinct core tenants of around 4 to 5 distinct therapies, meaning 100% fidelity is a really interesting concept anyway. But that’s an aside. The real point is that there is no causal relationship between any claims made about psychotherapy and the outcomes, despite postulation around distinct vocabulary despite their shared functional definition.
Fact #3. Our research methods with psychotherapy are sloppy at best, and irresponsible at worst.
Exclusion of known covariates (e.g., working alliance) is a major difficulty, as is the limited outcome criteria, their widely known flawed psychometrics which do not meet evidence-based standards, and attempts to assert inappropriate comparisons to control capacity within other RCT research. Most continue to use mere T-tests, not accounting for any of the complexity which exists in all forms of complex social interactions – of which therapy is one. If change is a complex phenomenon which we do not understand (see above), then we should feel pretty guilty about continuing to use what we know are limited methods at great cost to the public and our clients, assuming equal effort elsewhere might produce some evidence of actual, empirically supported (and not emotionally entrenched to) treatment factors.
Fact #4. We are wholly unable to predict the outcome a single client in psychotherapy.
We can tell you what will likely happen if there are a large number of you (see #2), but we do not know what will happen to you in treatment. We can’t predict if you will stay in, be “successful”, or anything else. We know some standard risk factors consistent with any type of matching phenomenon research (ie., “Birds of feather” in terms of style and expectation, and visual appearance produce higher engagement but equal results).
Fact #5. Therapy outcomes are the same across all therapists.
Some studies find small effect differences across years of experience (positively associated with outcomes), but consistent research finds no difference in orientation, training, degree type, or license in terms of therapy success, regardless of the definition of success (completion, change, engagement, etc.). The implication is that we have no evidence-based standards by which we can assess or improve competency as a function of training, due (likely in part) to our lack of commitment to clarity on the state of research on what is a causal mechanism for therapy is, and what it is not.
Fact #6. Change in psychotherapy is not dose responsive or standardized.
“While a large number of studies focused on the efficacy of one approach, cognitive-behavioral therapy (CBT), fewer studies have examined other widely utilized treatments including psychodynamic therapy, interpersonal psychotherapy, behavioral activation, problem-solving therapy, and emotion-focused therapy, among others. Most of these treatments have demonstrated preliminary efficacy necessitating the need for further study. In addition, while the largest body of literature is for CBT, the definition of CBT is not the same across all CBT studies. This heterogeneity limits the ability to make conclusions about the CBT model (p.53)…There is still lack of sufficient evidence on the enduring long-term effects of treatments for depression (p.54).”
– American Psychological Association’s Guidelines for the Treatment of Depression
Said another way, as approved by the American Psychological Association’s Council of Representatives, elected by its members:
“Overall, treatments for depression have a modest impact on alleviating symptoms of depression (with numbers-needed-to treat of about six to eight [meaning about six to eight need to be treated for each one that is successfully treated]). This reflects both the high rate of spontaneous recovery, placebo effects of treatment, and the modest effect of treatment (either psychotherapy or pharmacotherapy). It should also be noted that there is an important group of patients who do not recover, neither through spontaneous recovery nor treatments”
-2019 APA CLINICAL PRACTICE GUIDELINE for the Treatment of Depression Across Three Age Cohorts published by the GUIDELINE DEVELOPMENT PANEL FOR THE TREATMENT OF DEPRESSIVE DISORDERS
Yup. We can’t predict effects of treatment, some people it doesn’t work for at all, and low success rates (see number to treat), and we aren’t even sure what CBT “is”, much less the issue that the same “CBT” mechanisms can’t even be sure to be “CBT” (see earlier treatment fact #2).
Fact #7. We don’t know why any medications work.
There is no evidence that the supposed mechanisms (e.g., serotonin reuptake interruption) lead to the purported outcomes (e.g., less depressed), or that we are able to predict how an individual will respond to a given type of medication. Again, we cannot actually predict our intended goals (e.g., specific patient outcomes) any better than we could a hundred years ago.
Assessment Facts
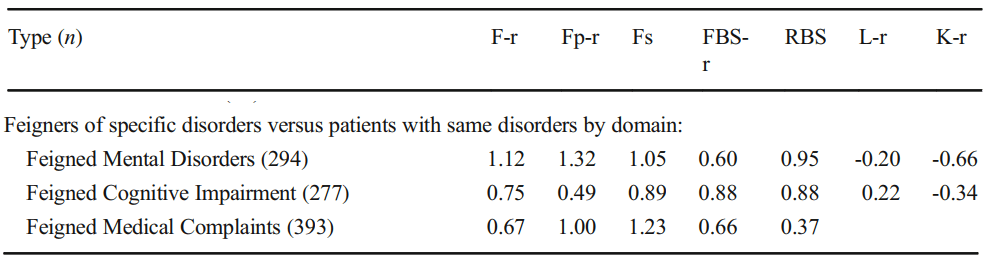
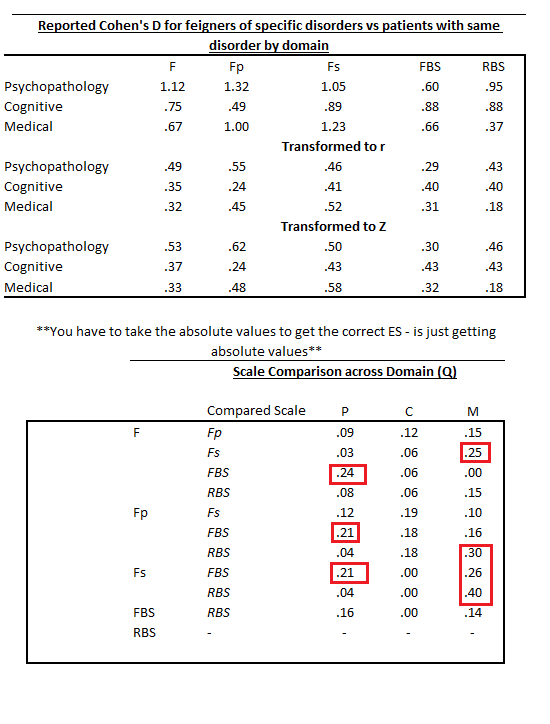
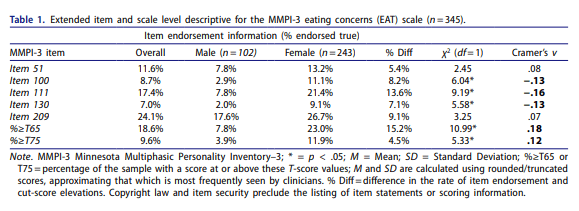
Fact #1. We have not improved measurement of invalid responding notably in quiet some time.
Scales tend to produce the same level of effect, depending on item scaling and contextual factors related to response style (E.g., disability evaluation, etc.), regardless of their theoretical basis or construction design. These effect sizes range from approximately .75 to 1.50. We can rule out folks with high probability by setting our scales that way, but we are poor at the detection of feigned symptoms which do not fall on normal distributions (e.g., memory or chance). Some have suggested an approximate .30 sensitivity “limit” even, terming it the “Larabee Limit”. We can reach these thresholds easily, regardless of method. We can sum scales (randomly selected, or theoretically derived), based items on theory and empirical support, or use infrequent-based approaches – they all produce the same outcomes. We can reduce or lengthen the scales, they all produce around the same effects. There aren’t major differences between theoretical taxonomical groups (See Fact #2), so we just get a lot of different tests that tell us different versions of the same thing. Once we are able to get past none of the scales mattering in what they measure or how they measure it, we can face the fact we do not know any causal reasons for elevation and can, most accurately, describe the data as being interpretable or not. We can describe certain other probabilities (e.g., malingering), but we cannot conclusively prove an internal state (motivation) in another. This issue revolves around the same issue in the treatment sciences in which causal factors are not known. Moreover, even given these limitations and ignoring them entirely, our study designs to validate these scales rarely consider any of their long-established moderators (e.g., sex, gender, ethnicity, etc. etc.). We have no real evidence of why, or how, people approach feigning across these tests, and have prioritized proposing theory rather than supporting it. Our approaches remain relatively unchanged for decades, with only the smallest adaptions being infused (e.g., incorporating an empirical keying-style approach to validity scale detection, in addition to clinical scales [RBS on MMPI and CBS on PAI], using infrequent approaches on a specific population with higher pathology to adjust the base rate of infrequency [Fp, Fs, etc.]). These changes, as noted previously, have not produced sizable or notable change in effects across decades of meta-analyses.
Fact #2. Even our most advanced diagnostic models are not truly taxonomical.
Linnaean delineation of species (e.g., classifications that determine if a bat is a mammal or a fishy) does not match our current approaches because we use covariance based assumptions, rather than appropriate modeling. Such a modeling difficulty is consistent with the mismatch between “Historical Science” and “Predictive Science” (). This terminology is from Harvard circa the early 1990s to describe different science tracks, based on different approaches to discovery. Darwin, when providing evidence of evolution, wasn’t able to manipulate time, but rather approached science from a distinct approach more fitting to the research question than the controllable predictive sciences. Perhaps psychology should adapt methods fit more for the Bayesian, probability-based model building, rather than strict empirical controls (e.g., Hi-Top, RCTs). Historical science approaches using “uniformitarian assumptions” and “history inference” are successful at producing predictable outcomes, but we do not use these methods in psychology effectively. Said more clearly within modern models of treatment research, perhaps idiographic meta-analysis will provide the strongest basis of truth upon which to expand into larger predictive models (erosion and plate tectonic deductions also worked like this as their current predictive models were developed).
Anyway, back to Netflix. Wheel of time needs to hurry up.